
This project is an interactive online experience that features music tastes from around the world and visually synthesizes the data to seek out and share trends with viewers, who can also add to the work. The gallery features AI-generated imagery using music trend data as seeds, which are combined to form one large work as a whole. The piece will allow viewers to see how music tastes might differ geographically, along with how we might express ourselves via sound analysis; a sort of “algorithmic synesthesia.”
Background
I have always been a very creative and musical person growing up, and recently I have been putting a lot of focus onto understanding new perspectives of those unlike myself. I wanted to choose something that would unite a large group of people who might not otherwise have something in common. Utilizing my artistic experience in graphic design and web development allows me to encompass a range of multimedia elements in creating this comprehensive piece.
I hope this piece puts into perspective a sense of community even among complete strangers, especially during a time where the world is so deeply divided. I also hope that the inclusion of visual elements serves to inspire the audience and encourage deeper collaborative thought. Viewers are able to add their own music taste to the piece, such that the dataset is constantly growing. Since everyone is able to add to the work, this piece is essentially always a work in progress that anyone can participate in.
Comparative Analysis
Every Noise at Once
- Visually plots different sounds from a wide variety of genres
- Allows for many different sorting methods
- Basic and straightforward design
Butterchurn Visualizer
- Generates visuals from music waveforms using uploaded files
- Random formula to display in real time
Milestones
Stage 1
- Further research comps, APIs, and potential AI solutions
- Become familiar with Spotify API
- Consider what data needs to be gathered
Stage 2
- Design and finalize base concept of website
- Finalize what data needs to be gathered
- Design database schema
- Gather sample data
- Test sample synthesis techniques
Stage 3
- Build gallery website
- Visually polish website
APIs
As I conducted research and visualized the creation process for this project, I began to realize that the extent of the APIs required to coordinate the final product was more than I initially anticipated. I finally settled on utilizing the Spotify API to retrieve audio features, and spent time becoming more familiar with the API and the relevant information it can provide. I also chose to use the Google Maps API for reverse-geocoding, which would allow for users’ locations to influence the final prompt.
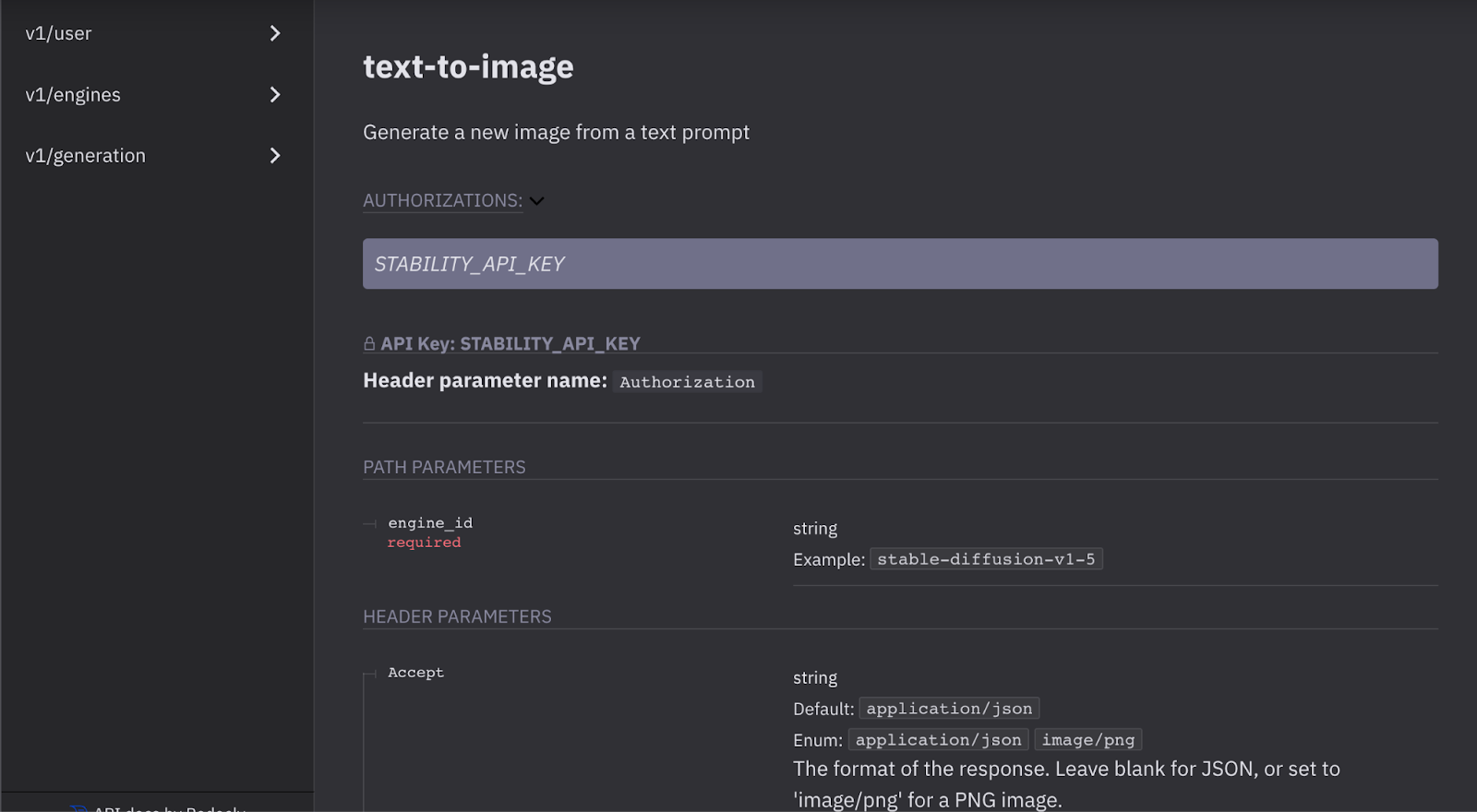
Finally, I used Stability.ai for stable diffusion via DreamStudio for AI art generation. The final web application is coded in HTML, CSS, JavaScript, and PHP on the server-side to handle API calls.
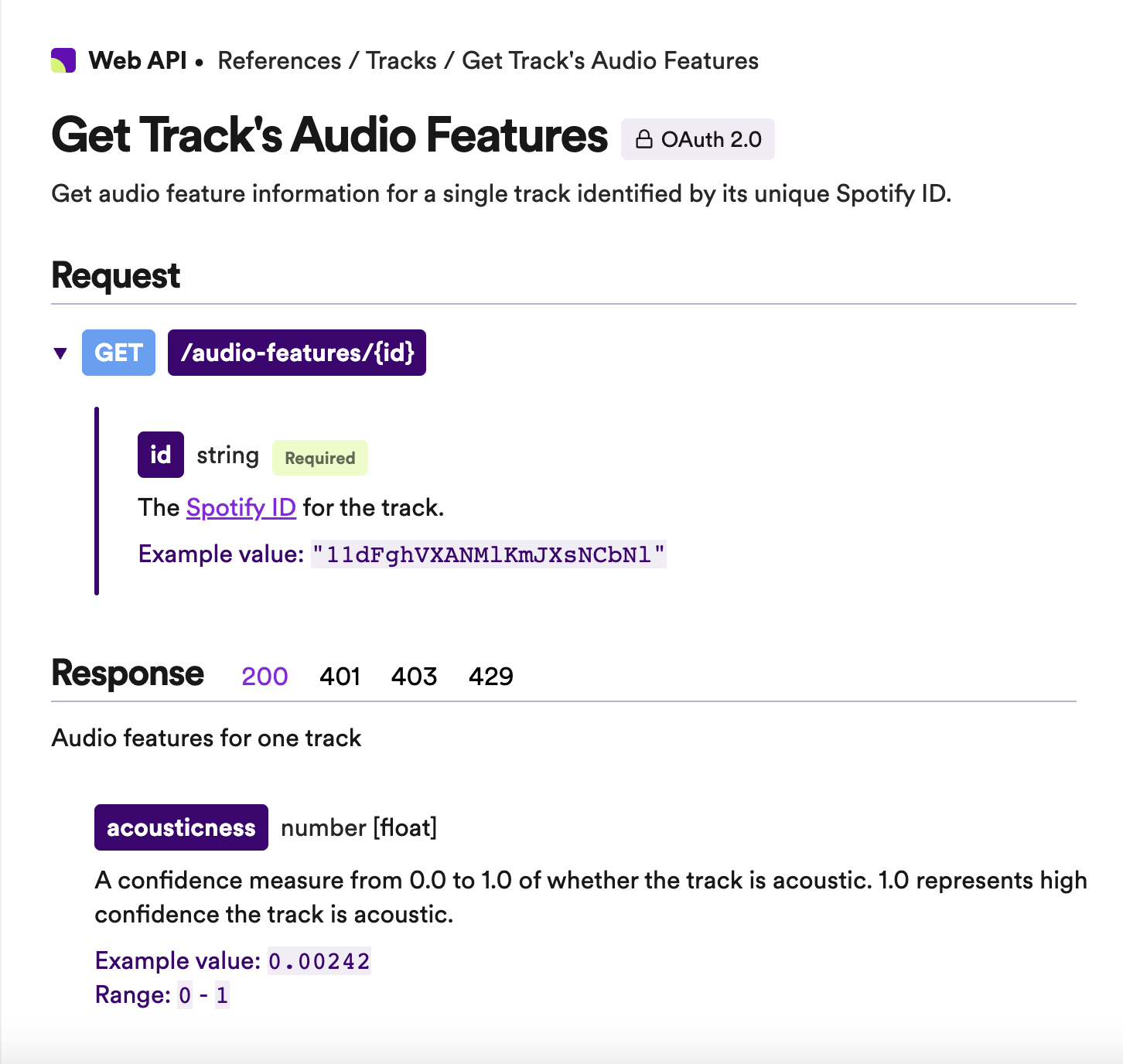
Spotify’s Audio Features
The following audio features are calculated using advanced audio analysis techniques, such as signal processing and machine learning algorithms. They are designed to capture different aspects of the music, such as its rhythm, timbre, harmony, and emotional content.
- Acousticness
- Danceability
- Energy
- Instrumentalness
- Liveness
- Loudness
- Speechiness
- Tempo
- Valence
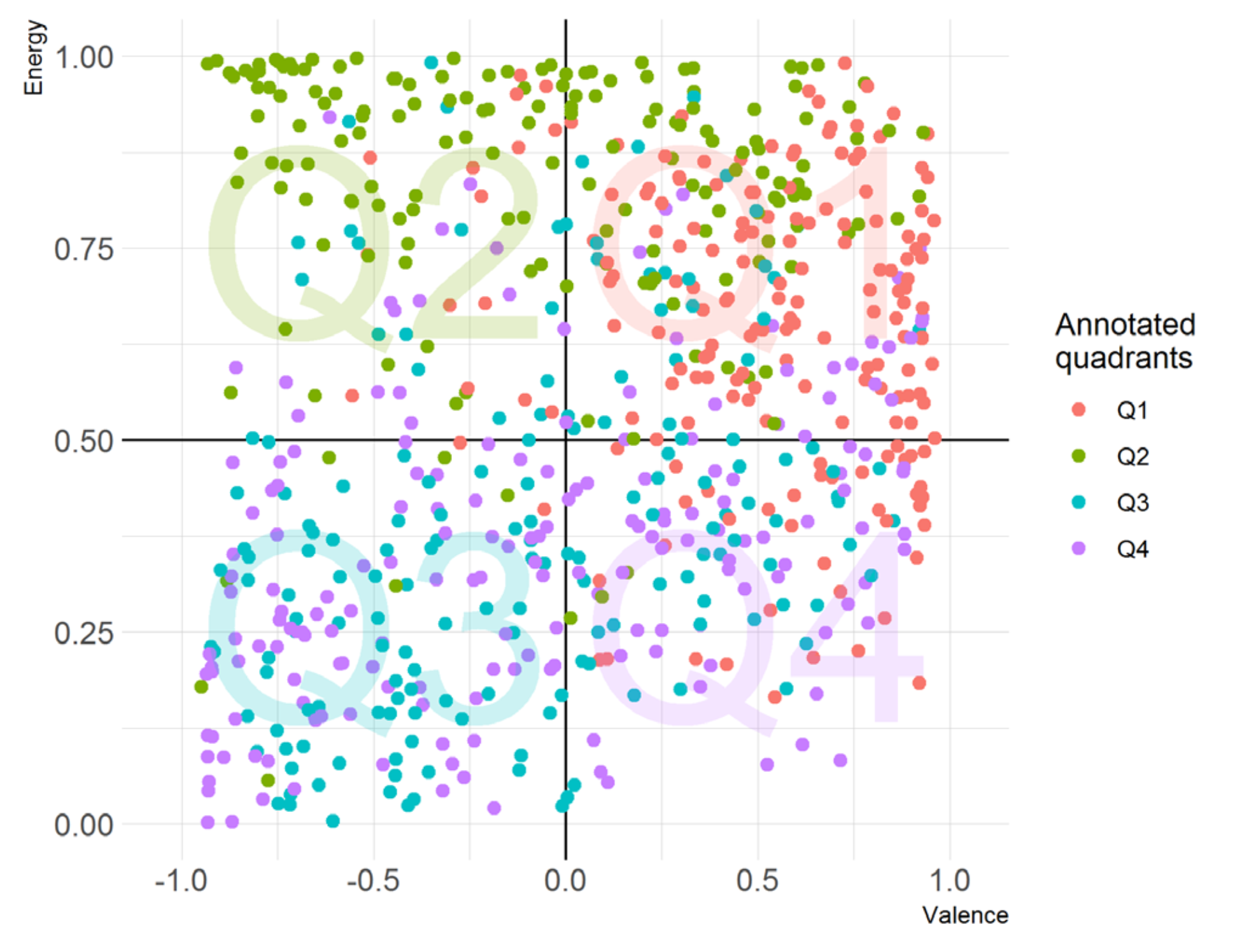
Mockups
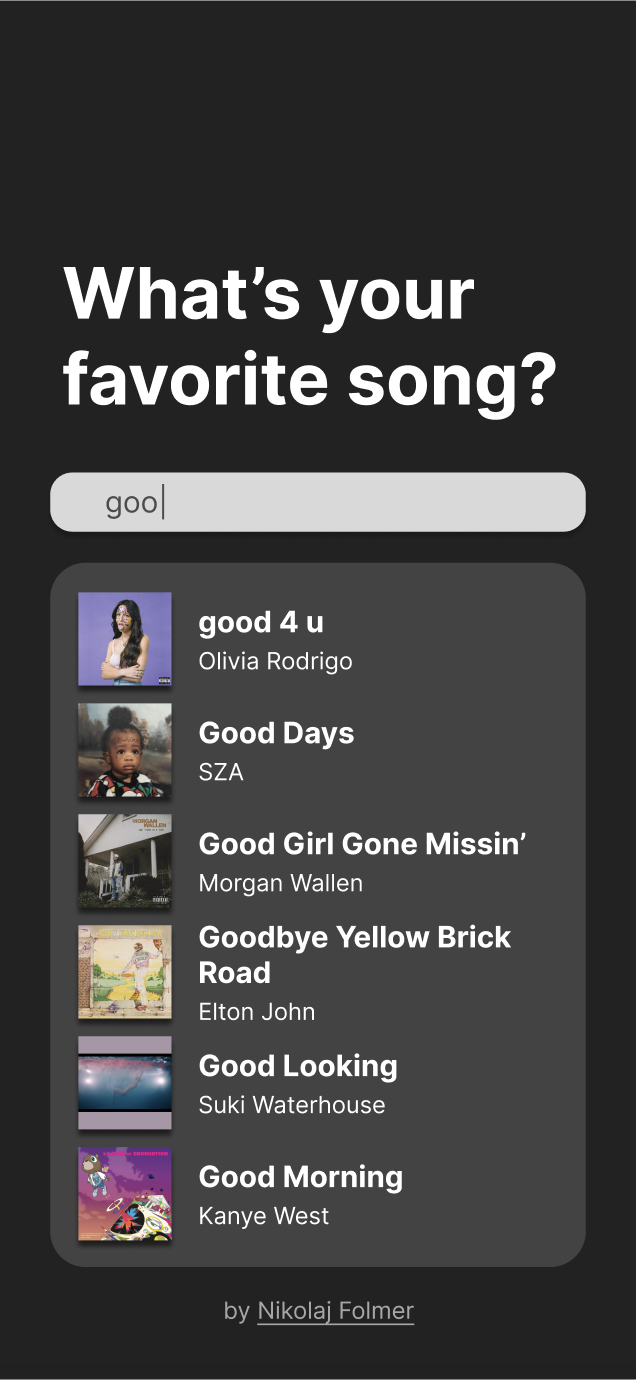
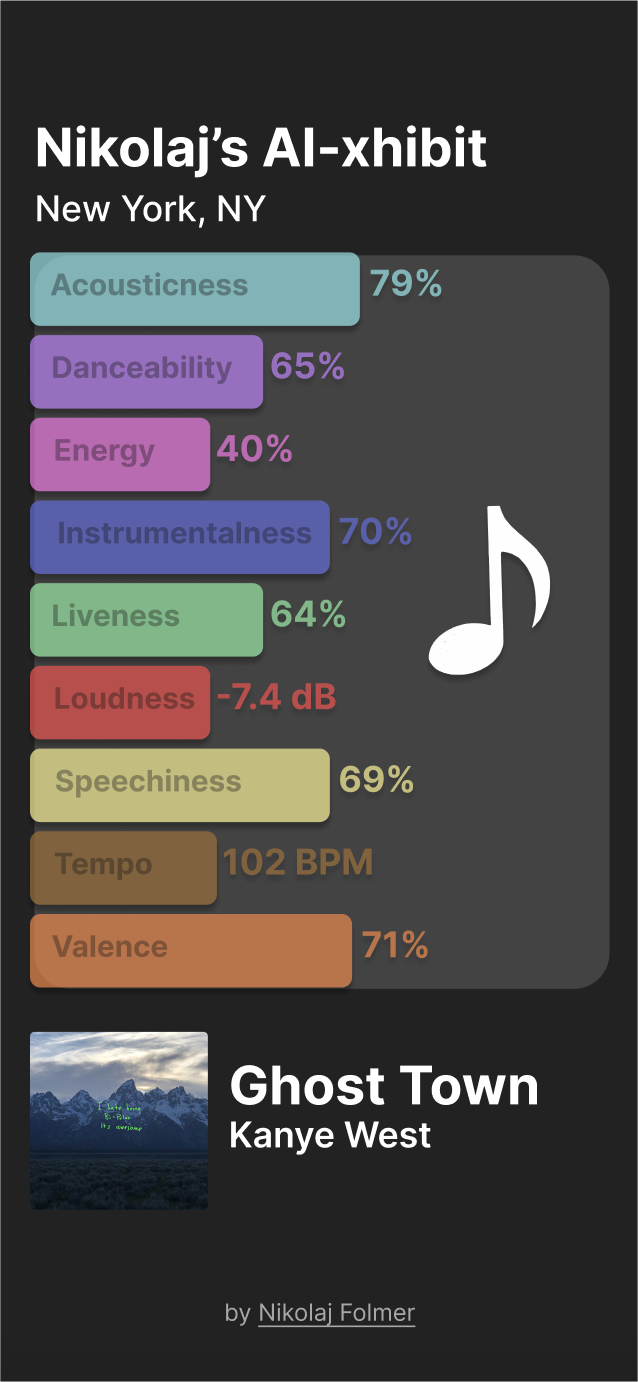
Image Prompt Generation
One of the biggest hurdles I encountered was deciding how I would generate an image prompt for the AI based on each song’s audio features. I played around with various stable diffusion platforms to test what phrasing might work best, while maintaining a balance between uniqueness and consistency.
I finally settled on using a reference table, which I created by assigning certain phrases to each range of audio feature values. The PHP script then builds a prompt string based on a song’s audio feature values and their correspondence to the reference table.
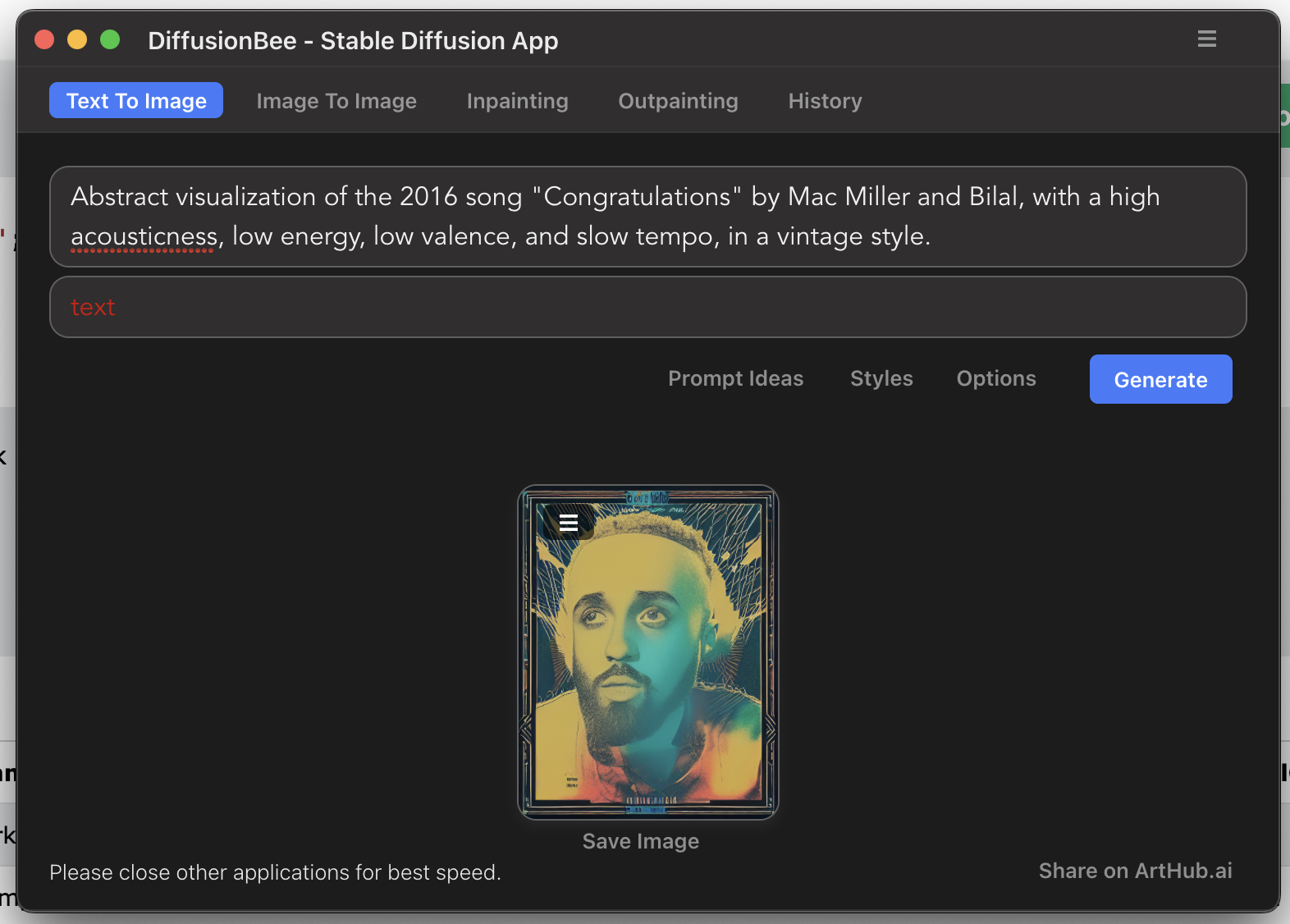
One small issue I encountered with prompting was that the DreamStudio API does not accept inappropriate words—which is not ideal for song titles that contain explicit language—so I had to write a function to sanitize the prompt before sending it over.